Fit a linear model with (sparse) group regularisation
Source:R/group_sparse_lm.R, R/group_sparse_lm_aliases.R
group_sparse_lm.RdAdjust a linear model with (sparse) group regularization, that is, a mixture of an element-wise \(\ell_1\) norm and a group-wise mixed-norm (either \(\ell_1/\ell_2\), \(\ell_1/\ell_\infty\) or cooperative). We also add a (possibly structured) \(\ell_2\)-norm (ridge-like). The solution path is computed on an automatically tuned grid of values for the sparse group penalty. The mixture coefficient and the amount of ridge-like regularization are fixed by the user. See details for the criterion optimized.
Usage
group_sparse_lm(
x,
y,
group,
type = c("l2", "coop", "linf"),
lambda1 = NULL,
lambda2 = 0.01,
alpha = 0,
weights = rep(1, nrow(x)),
penscale = sqrt(tabulate(group)),
struct = Matrix::Diagonal(ncol(x), 1),
intercept = TRUE,
normalize = TRUE,
refit = FALSE,
nlambda1 = ifelse(is.null(lambda1), 100, length(lambda1)),
minratio = 0.01,
maxfeat = ifelse(lambda2 < 0.01, min(2 * nrow(x), ncol(x)), min(4 * nrow(x), ncol(x))),
beta0 = numeric(ncol(x)),
control = list()
)
group_lasso(
x,
y,
group,
lambda1 = NULL,
lambda2 = 0,
weights = rep(1, nrow(x)),
penscale = sqrt(tabulate(group)),
intercept = TRUE,
normalize = TRUE,
nlambda1 = ifelse(is.null(lambda1), 100, length(lambda1)),
minratio = 0.01,
maxfeat = ncol(x),
beta0 = numeric(ncol(x)),
control = list(method = "quadra")
)
group_l1linf(
x,
y,
group,
lambda1 = NULL,
lambda2 = 0,
weights = rep(1, nrow(x)),
penscale = sqrt(tabulate(group)),
intercept = TRUE,
normalize = TRUE,
nlambda1 = ifelse(is.null(lambda1), 100, length(lambda1)),
minratio = 0.01,
maxfeat = ncol(x),
beta0 = numeric(ncol(x)),
control = list()
)
coop_lasso(
x,
y,
group,
lambda1 = NULL,
lambda2 = 0,
weights = rep(1, nrow(x)),
penscale = sqrt(tabulate(group)),
intercept = TRUE,
normalize = TRUE,
nlambda1 = ifelse(is.null(lambda1), 100, length(lambda1)),
minratio = 0.01,
maxfeat = ncol(x),
beta0 = numeric(ncol(x)),
control = list()
)
sparse_group_lasso(
x,
y,
group,
lambda1 = NULL,
lambda2 = 0,
alpha = 0.5,
weights = rep(1, nrow(x)),
penscale = sqrt(tabulate(group)),
intercept = TRUE,
normalize = TRUE,
nlambda1 = ifelse(is.null(lambda1), 100, length(lambda1)),
minratio = 0.01,
maxfeat = ncol(x),
beta0 = numeric(ncol(x)),
control = list()
)
sparse_group_l1linf(
x,
y,
group,
lambda1 = NULL,
lambda2 = 0,
alpha = 0.5,
weights = rep(1, nrow(x)),
penscale = sqrt(tabulate(group)),
intercept = TRUE,
normalize = TRUE,
nlambda1 = ifelse(is.null(lambda1), 100, length(lambda1)),
minratio = 0.01,
maxfeat = ncol(x),
beta0 = numeric(ncol(x)),
control = list()
)
sparse_coop_lasso(
x,
y,
group,
lambda1 = NULL,
lambda2 = 0,
alpha = 0.5,
weights = rep(1, nrow(x)),
penscale = sqrt(tabulate(group)),
intercept = TRUE,
normalize = TRUE,
nlambda1 = ifelse(is.null(lambda1), 100, length(lambda1)),
minratio = 0.01,
maxfeat = ncol(x),
beta0 = numeric(ncol(x)),
control = list()
)Arguments
- x
matrix of features, possibly sparsely encoded (experimental). Do NOT include intercept. When normalized is
TRUE, coefficients will then be rescaled to the original scale.- y
response vector.
- group
vector of integers indicating group belonging. Must match the number of column in
x. Must be SORTED integers starting from 1.- type
string indicating the sparse-group variant to be fitted. Could be "l2", "coop", or "linf". Default is "l2" (regular Group-Lasso)
- lambda1
sequence of decreasing \(\ell_1\)-penalty levels. If
NULL(the default), a vector is generated withnlambda1entries, starting from a guessed levellambda1.maxwhere only the intercept is included, then shrunken tominratio*lambda1.max.- lambda2
real scalar; tunes the \(\ell_2\) penalty in the Elastic-net. Default is 0.01. Set to 0 to recover the Lasso.
- alpha
real scalar in (0,1); tunes mixture between \(\ell_1\) group penalties. Default is 0.0 (standard group-lasso).
- weights
vector with real positive values that weight the observations (like in weighted least square). Default sets all weights to 1.
- penscale
vector with real positive values that weight the penalty of each feature. Default sets all weights to 1.
- struct
matrix structuring the coefficients, possibly sparsely encoded. Must be at least positive semidefinite (this is checked internally). If
NULL(the default), the identity matrix is used. See details below.- intercept
logical; indicates if an intercept should be included in the model. Default is
TRUE.- normalize
logical; indicates if variables should be normalized to have unit L2 norm before fitting. Default is
TRUE.- refit
logical: indicates if the non null coefficients should be refit to avoid excessive bias. Default is FALSE. Can be changed later (both raw and refit coefficients are stored).
- nlambda1
integer that indicates the number of values to put in the
lambda1vector. Ignored iflambda1is provided.- minratio
minimal value of \(\ell_1\)-part of the penalty that will be tried, as a fraction of the maximal
lambda1value. A too small value might lead to instability at the end of the solution path corresponding to smalllambda1combined with \(\lambda_2=0\). The default value tries to avoid this, adapting to the '\(n<p\)' context. Ignored iflambda1is provided.- maxfeat
integer; limits the number of features ever to enter the model; i.e., non-zero coefficients for the Elastic-net: the algorithm stops if this number is exceeded and
lambda1is cut at the corresponding level. Default ismin(nrow(x),ncol(x))for smalllambda2(<0.01) andmin(4*nrow(x),ncol(x))otherwise. Use with care, as it considerably changes the computation time.- beta0
a starting point for the vector of parameter. By default, will initialized zero. May save time in some situation.
- control
list of argument controlling low level options of the algorithm –use with care and at your own risk– :
verbose: integer; activate verbose mode –this one is not too risky!– set to0for no output;1for warnings only, and2for tracing the whole progression. Default is1. Automatically set to0when the method is embedded within cross-validation or stability selection.timer: logical; use to record the timing of the algorithm. Default isFALSE.maxiterthe maximal number of iteration used in the active set algorithm to solve the problem for a given value of lambda1 . Default is 50.methoda string for the underlying solver used. Either"quadra","fista"or"pgd". Default is"quadra".factmatBoolean indicating if matrix factorization should be used to solve the sub-system. IfTRUE(the default), a Cholesky decomposition is maintained along the path. IfFALSE, the sub-system are solved with a conjugate gradient algorithm.thresholda threshold for convergence. The algorithm stops when the optimality conditions are fulfill up to this threshold. Default is1e-6.monitorindicates if a monitoring of the convergence should be recorded, by computing a lower bound between the current solution and the optimum: when'0'(the default), no monitoring is provided; when'1', the bound derived in Grandvalet et al. is computed; when'>1', the Fenchel duality gap is computed along the algorithm.
Value
an object with class SparseGroupFit, inheriting from QuadrupenFit.
Details
The optimized criterion is the following:
βhatλ1,λ2 =
argminβ 1/2 RSS(β) + λ1
[(1-α) Ωg(β) + α | D β |1]
+ λ2/2 βT S β,
where \(\Omega_g\) is the group-wise mixed norm:
\(\ell_1/\ell_2\) (Group-Lasso),
\(\ell_1/\ell_\infty\), or cooperative (Clime), controlled
by the type argument; \(D\) is a diagonal matrix whose
diagonal terms are given by penscale; \(\alpha\)
tunes the mixture between the group and element-wise penalties;
and \(S\) is the \(\ell_2\) structuring matrix provided
via struct, a positive semidefinite matrix (possibly of
class Matrix).
See also
See also QuadrupenFit
Examples
## Simulating multivariate Gaussian with blockwise correlation
## and piecewise constant vector of parameters
beta <- rep(c(0,1,0,-1,0), c(25,10,25,10,25))
grp <- rep(1:5, c(25,10,25,10,25))
cor <- 0.75
Soo <- toeplitz(cor^(0:(25-1))) ## Toeplitz correlation for irrelevant variables
Sww <- matrix(cor,10,10) ## bloc correlation between active variables
Sigma <- Matrix::bdiag(Soo,Sww,Soo,Sww,Soo)
diag(Sigma) <- 1
n <- 50
x <- as.matrix(matrix(rnorm(95*n),n,95) %*% chol(Sigma))
y <- 10 + x %*% beta + rnorm(n,0,10)
## Various sparse group linear models without/with an additional l2 regularization term
## and with structuring prior
labels <- rep("irrelevant", length(beta))
labels[beta != 0] <- "relevant"
## Group-Lasso
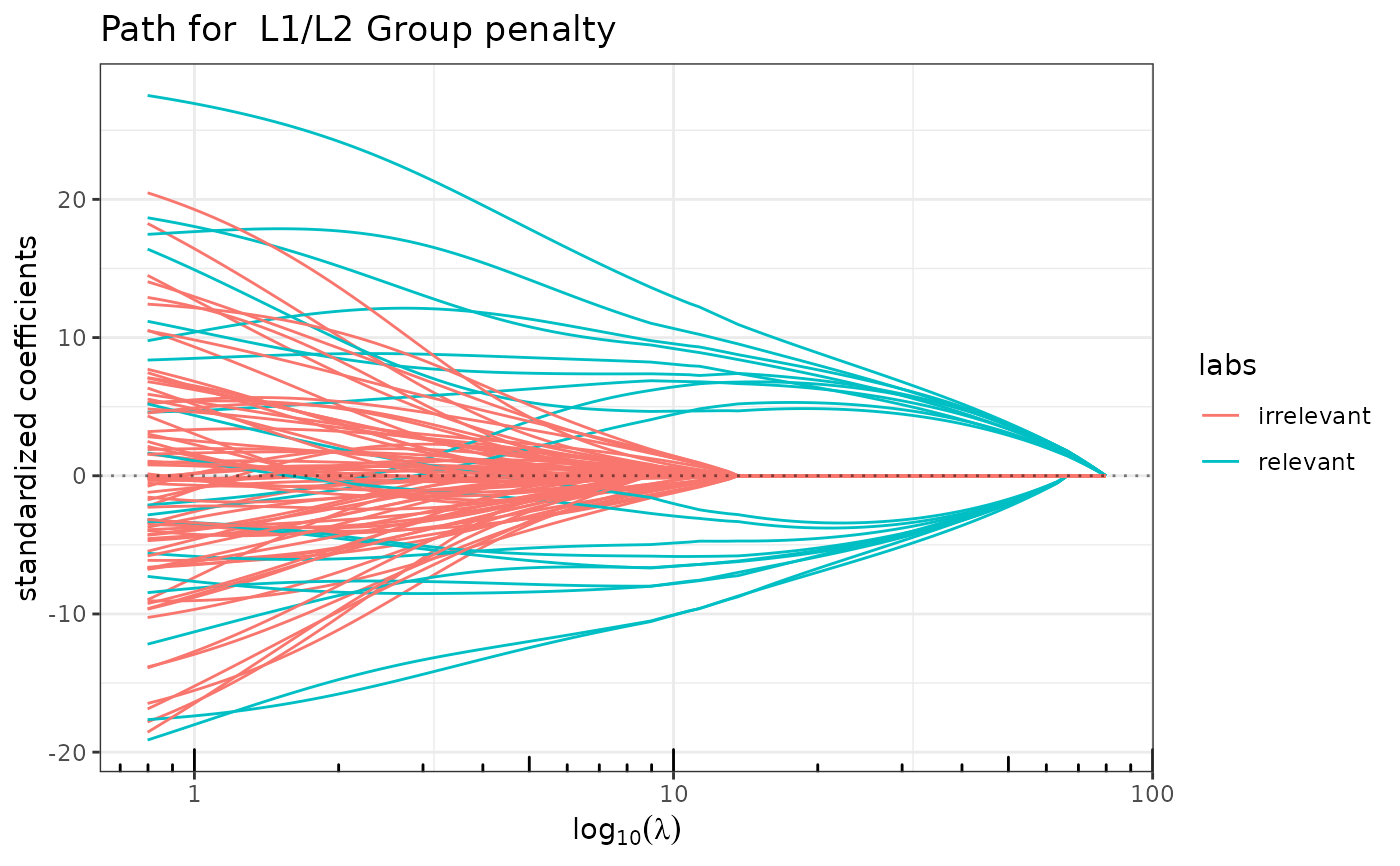
plot(group_lasso(x, y, grp), label=labels)
 ## Sparse Group-Lasso
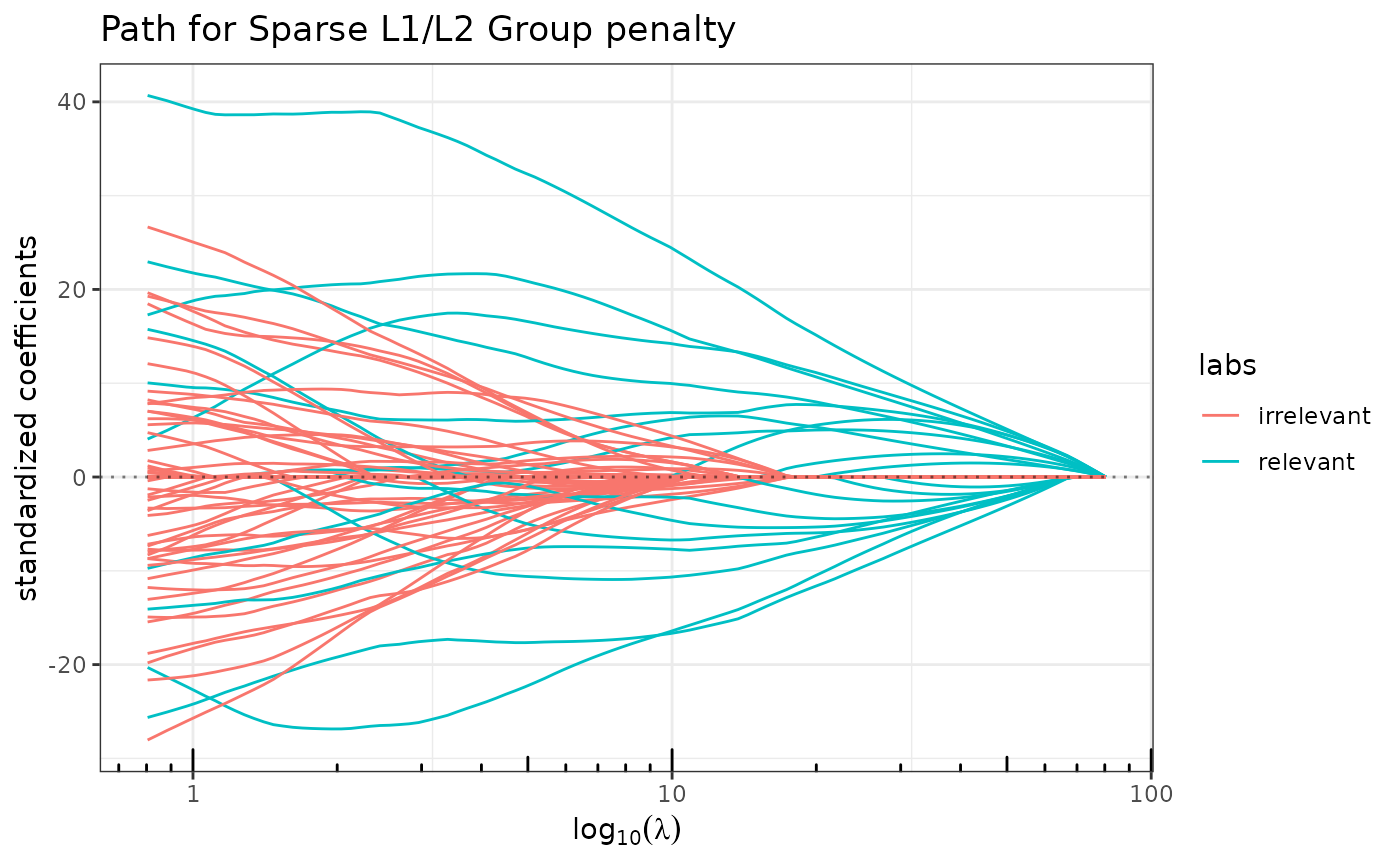
plot(sparse_group_lasso(x, y, grp, alpha = 0.75), label=labels)
## Sparse Group-Lasso
plot(sparse_group_lasso(x, y, grp, alpha = 0.75), label=labels)
 if (FALSE) { # \dontrun{
## Sparse Group-Lasso + L2 regularization
plot(group_sparse_lm(x, y, grp, type = "l2", alpha = .75, lambda2=.5),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "l2", alpha = .75, lambda2=10),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "l2", alpha = .75, lambda2=10,
struct=solve(Sigma)), label=labels)
## Group-Lasso L1/LINF
plot(group_l1linf(x, y, grp), label=labels)
## Sparse Group-Lasso L1/LINF
plot(sparse_group_l1linf(x, y, grp, alpha = 0.75), label=labels)
## Sparse L1/LINF Group-Lasso + L2 regularization
plot(group_sparse_lm(x, y, grp, type = "linf", alpha = .75, lambda2=.5),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "linf", alpha = .75, lambda2=10),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "linf", alpha = .75, lambda2=10,
struct=solve(Sigma)), label=labels)
## Cooperative-Lasso
plot(coop_lasso(x, y, grp), label=labels)
## Sparse Cooperative-Lasso
plot(sparse_coop_lasso(x, y, grp, alpha = 0.75), label=labels)
## Sparse Cooperative-Lasso + L2 regularization
plot(group_sparse_lm(x, y, grp, type = "coop", alpha = .75, lambda2=.5),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "coop", alpha = .75, lambda2=10),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "coop", alpha = .75, lambda2=10,
struct=solve(Sigma)), label=labels)
} # }
if (FALSE) { # \dontrun{
## Sparse Group-Lasso + L2 regularization
plot(group_sparse_lm(x, y, grp, type = "l2", alpha = .75, lambda2=.5),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "l2", alpha = .75, lambda2=10),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "l2", alpha = .75, lambda2=10,
struct=solve(Sigma)), label=labels)
## Group-Lasso L1/LINF
plot(group_l1linf(x, y, grp), label=labels)
## Sparse Group-Lasso L1/LINF
plot(sparse_group_l1linf(x, y, grp, alpha = 0.75), label=labels)
## Sparse L1/LINF Group-Lasso + L2 regularization
plot(group_sparse_lm(x, y, grp, type = "linf", alpha = .75, lambda2=.5),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "linf", alpha = .75, lambda2=10),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "linf", alpha = .75, lambda2=10,
struct=solve(Sigma)), label=labels)
## Cooperative-Lasso
plot(coop_lasso(x, y, grp), label=labels)
## Sparse Cooperative-Lasso
plot(sparse_coop_lasso(x, y, grp, alpha = 0.75), label=labels)
## Sparse Cooperative-Lasso + L2 regularization
plot(group_sparse_lm(x, y, grp, type = "coop", alpha = .75, lambda2=.5),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "coop", alpha = .75, lambda2=10),
label=labels)
plot(group_sparse_lm(x, y, grp, type = "coop", alpha = .75, lambda2=10,
struct=solve(Sigma)), label=labels)
} # }